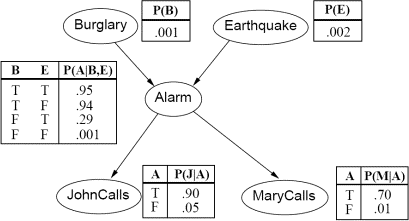
Apply Gibbs sampling to carry out approximate inference in Bayesian networks. You should estimate the (marginal) probability distribution of several variables in a Bayesian network, given the settings of a subset of the other variables (evidence). Implement the Gibbs algorithm in MATLAB based on the code provided Gibbs.zip11 and test it on the three Bayesian networks shown below. Your code should run Gibbs sampling a specified number of iterations in order to estimate the required probability distributions. Since Gibbs sampling is a randomized, iterative algorithm, the actual number of iterations needed to estimate probabilities is an important issue, that will be explored as part of this assignment.
|
|
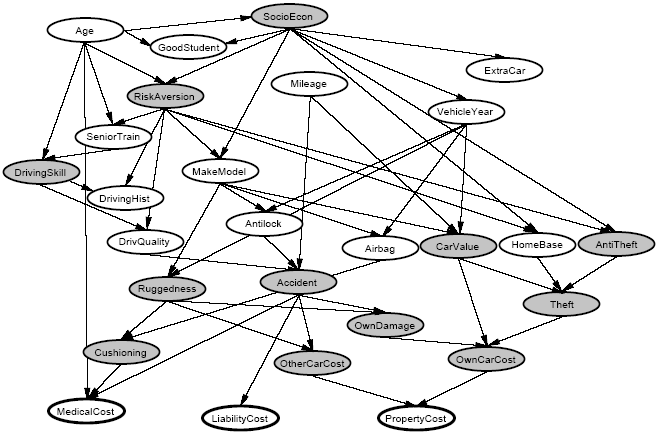
The network has 27 variables (usually the 12 shaded variables are considered hidden or unobservable, while the other 15 are observable) and over 1400 parameters. An insurance company would be interested in predicting the bottom three "cost" variables, given all or a subset of the other observable variables. The network has been provided in the file insurance.mat.
Run Gibbs sampling for a 1000 times for 1, 10, 100, and 1000 steps starting from random intial values for the hidden variables (drawn from a uniform distribution) and plot the dependence of the resulting probability distribution (obtained for the 1000 trials) on the number of steps. Because some of the factors of the joint probability distribution are 0 you have to make sure that the probability of the intial state of the random variables is larger than zero (if not choose another initial state).
How long ist the burn-in time (number of steps) that is required to sample from the stationary probability distribution?
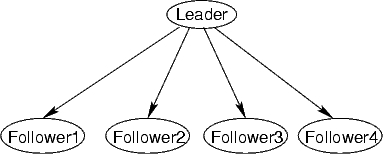
Each network in this family has a single "leader" variable, and some number of "follower" variables as shown in Fig. 8. The idea is that the leader selects a bit at random (0 or 1 with equal probability), and then all of the followers choose their own bits, each one copying the leader's bit with 90% probability, or choosing the opposite of the leader's bit with 10% probability. Leader-follower networks with ![]() followers have been provided in the files leader-follower-k.bn for
followers have been provided in the files leader-follower-k.bn for
![]() .
.
What is the marginal probability distribution for the leader variable, in the absence of any evidence (i.e., none of the other variables have been set to specified values)?