


Next: RL application I: On-
Up: MLB_Exercises_2010
Previous: RL theory I [3
Assume that for a given continuing MDP with discount factor
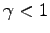 we modify the reward signal by either
we modify the reward signal by either
- a)
- adding a constant
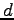 to all rewards
to all rewards
- b)
- multiplying every reward with a constant
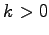
- c)
- linearly transforming the reward signal to
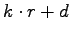 ,
,
Can this change the optimal policy of the MDP? Express for all three cases the new state values in terms of
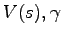 and the constants (where
and the constants (where 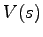 is the optimal value of state
is the optimal value of state 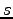 under the original reward function).
under the original reward function).
Now consider the following modifications for deterministic MDPs:
- d)
- Let
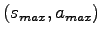 be the state-action pair that leads to the highest possible immediate reward
be the state-action pair that leads to the highest possible immediate reward
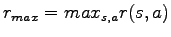 in the MDP. Set
in the MDP. Set
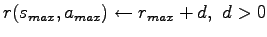
- e)
- Let
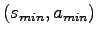 be the state-action pair that leads to the lowest possible immediate reward
be the state-action pair that leads to the lowest possible immediate reward
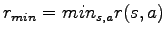 in the MDP. Set
in the MDP. Set
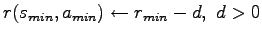
For simplicity, you can assume in both cases that the minimum/maximum is unique, i.e. it is taken on exactly at one state-action pair. Can you guarantee for arbitrary MDPs that the optimal policy stays the same? If not, show a counterexample.
Next: RL application I: On-
Up: MLB_Exercises_2010
Previous: RL theory I [3
Haeusler Stefan
2011-01-25